신기술 동향
다른 기사 보기
인공지능 반도체 개발 동향 및 맞춤형 교육과정
기고자. 서울대학교 혁신융합대학 차세대반도체사업단 이재학 객원교수기고자. 서울대학교 공과대학 전기정보공학부 이혁재 교수
1. 서론


2016년 알파고의 성공으로 첨단기술의 중심으로 자리 잡은 인공지능(AI) 기술은 2023년 챗GPT 열풍으로 대표되는 생성형 AI 기술의 등장으로 대중적인 관심을 받으며 산업 전 분야로 확산되고 있다. 생성형 AI 기술은 주로 클라우드 컴퓨팅 기술을 사용한다. 스마트 디바이스에서 수집한 정보를 클라우드 서버로 전송하고 AI 알고리즘 분석을 거친 뒤 그 결과를 다시 디바이스로 보내는 방식이다. 2024년도에는 온디바이스(On-Device) AI가 장착된 스마트폰이 등장하였다. 온디바이스 AI는 클라우드 컴퓨팅에 의존하지 않고 디바이스에서 자체적으로 AI 학습과 연산을 수행하는 기술이다. 클라우드 의존성이 없고 보안 위협에 노출될 우려가 적으며 빠르게 반응하는 장점이 있다. 온디바이스 AI로 인하여 새로운 서비스가 많이 등장할 것으로 기대되는데 효율적인 스마트 디바이스를 만들기 위해서는 그 서비스에 특화된 다양한 AI 반도체 개발이 요구되고 있어 국내 반도체 기업들이 신규 사업 기회를 맞이할 것으로 기대된다. 이와 관련하여 AI 반도체 인력 양성 수요도 증가되고 있다.
2. 인공지능 반도체 개발 동향
인공지능(AI) 반도체는 AI 알고리즘을 효율적으로 구현할 수 있는 반도체로 정의된다. 또 AI 모델의 학습과 추론을 저전력에 고속으로 최적 수행할 수 있어 특히 효율적인 반도체다. AI 반도체는 AI 시스템 구현 목적에 따라 학습용과 추론용으로 구분되며 두 과정을 반복 실행하여 최적의 답을 찾는 데 특화되어 있다. AI 반도체는 1세대(CPU, GPU), 2세대(FPGA, ASIC), 3세대(PIM, 뉴로모픽)로 구분된다. AI 반도체의 구분과 특징 및 전망을 [그림1]에 보인다.
기존의 범용 프로세서 CPU(Central Processing Unit)는 대량의 데이터 처리·연산에 적합하지 못한 구조이다. GPU(Graphic Processing Unit)는 당초 고화질 그래픽 연산을 처리하기 위해 개발되었으나, 딥러닝의 반복적인 연산을 대부분 고도화된 병렬 연산에 그대로 대응시킬 수 있게 되어 AI 연산 가속의 핵심 반도체로 역할을 수행하고 있다.
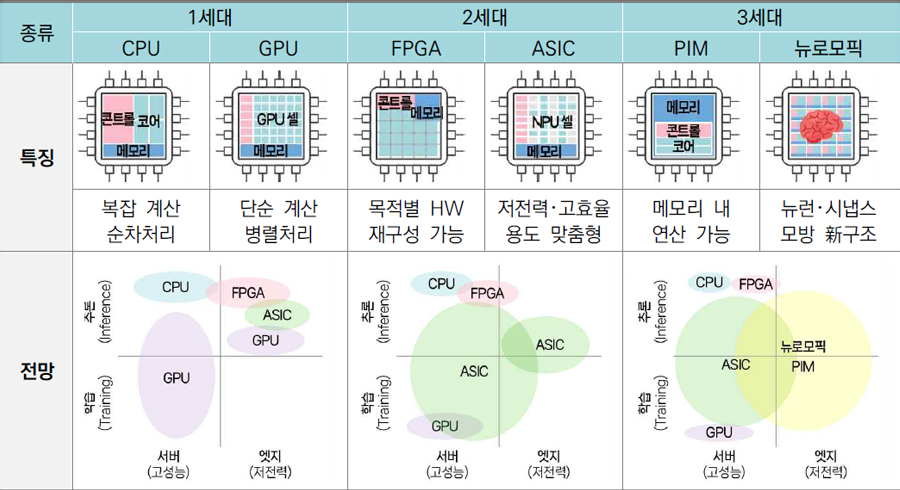
FPGA(Field-Programmable Gate Array)는 목적에 따라 반복 프로그래밍이 가능한 반도체 구조로 짧은 개발 시간과 높은 유연성에 따라 AI의 잦은 알고리즘 변화에 효과적으로 대응 가능하다. 반면 높은 가격으로 범용성은 떨어져 초기 개발용으로 주로 사용된다. ASIC(Application Specific Integrated Circuit)은 명확한 응용과 목적을 가진 시스템을 저전력으로 구동하기 위해 활용하는 주문형 SoC로 디바이스와 서비스에 특화된 AI 반도체를 개발하고 생산하기에 유리하다.
AI 기술 발전이 가속되며 모델의 매개변수와 데이터양이 급증했다. 따라서 기존 폰노이만 구조로는 전체 시스템에서 메모리 성능의 벽에 부딪히는 메모리벽(Memory Wall)과 데이터 전달량 급증으로 인한 막대한 에너지 소모의 병목 현상을 겪게 된다. PIM(Processing-In-Memory) 반도체는 앞의 병목 현상을 해결하기 위해 메모리 내에서 AI의 주요 연산을 수행, 메모리-연산장치 간 데이터 전달을 현저히 줄이고 에너지 소모를 감소시킨다.
뉴로모픽 반도체는 뇌과학 분야에 근간한 연구 및 개발이 활발히 진행 중이며, 이를 통해 뇌의 동작 및 학습 구조에 관한 연구가 진행 중이다. 인간 뇌 속의 ‘연산’은 폰노이만 구조와는 전혀 다르다. 인간의 뇌는 행동 잠재력(스파이크)이라 불리는 시간적 사건에 대해 동작한다. 뉴로모픽 반도체 연구는 2000년대 중반부터 유럽과 미국 등에서 원천기술 확보를 위한 국가 주도 R&D 사업으로 시작되었다. 주요 연구 결과들은 다음과 같다.
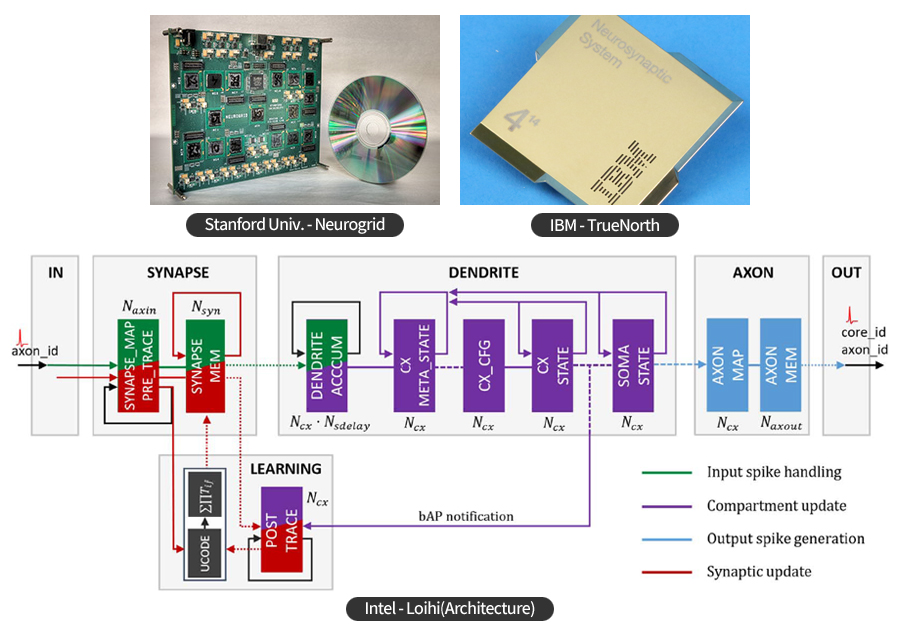
스탠포드 대학의 Neurogrid는 기본 블록인 하나의 Neurocore내에 256x256개의 아날로그/디지털 혼합 설계 방식의 뉴런들이 2차원 배열 형태로 구성되어 있고 각 뉴런은 블록 전체에 브로드캐스팅되는 버스로 연결되어 있다. 최대 228 Dhrystone TIPS의 성능을 가지며 518,400개의 프로세서로 확장될 수 있는 구조를 이용해 10억개 뉴런의 시뮬레이션이 가능하다.
IBM의 TrueNorth는 4,096개의 코어로 인간 뇌 100만 개의 뉴런(neuron)과 2억 5,600만 개 시냅스(synapse)를 재현하고 초기 뇌 모사 컴퓨팅 구조로 70mW의 전력으로 실시간 연산을 통해 인간처럼 물체를 식별하고 패턴을 인식하는 등 처리가 가능하다.
인텔의 Loihi는 비동기식 SNN(Spiking neural network) 알고리즘을 구현하고 128개의 뉴로모픽 코어와 3개의 lakemont x86 코어로 구성된다. 최대 4096개의 온-칩 코어와 최대 16,384 개의 칩을 지원한다. 다양한 스파이크 신호 프로그래밍 기능과 프로그래밍 가능한 뉴런 및 고속 이더넷 인터페이스를 지원한다.
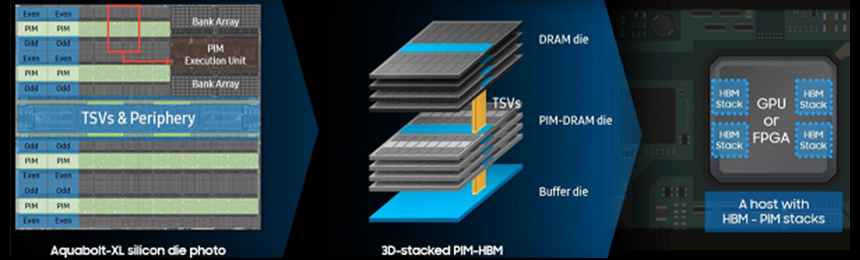
삼성전자는 DRAM 메모리와 AI 연산기를 하나로 결합한 HBM-PIM을 발표하였다. 온디바이스 AI 와 관련하여 음성 인식, 번역, 챗봇 등에서 2배 이상 성능 향상을 보인다.
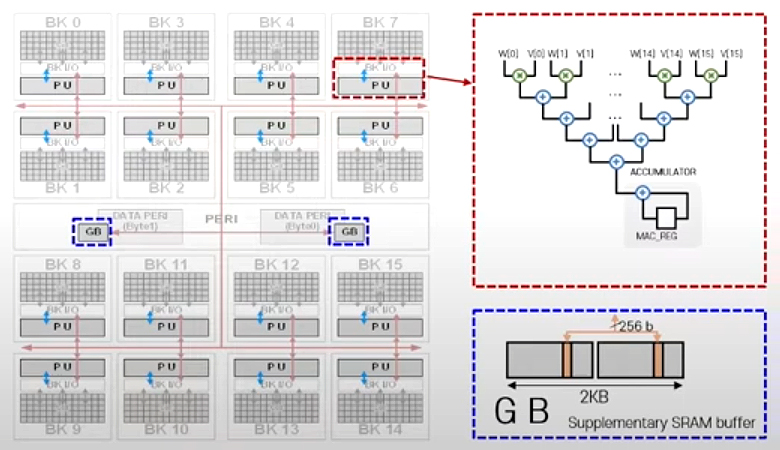
SK 하이닉스는 HBM2E 구조의 GPU 같은 이종 컴퓨팅 장치용 메모리를 위한 GDDR6-AiM 칩을 발표하였다. Non-PIM 기반 시스템과 GPU보다 각각 약 10배, 54배의 성능 향상을 보이고 1.25V에서 구동되어 전력 효율 향상을 보인다.
AI 반도체는 활용 목적에 따라 클라우드 서버용과 온디바이스용으로 분화하여 발전하고 있다. 두 분야 모두 ASIC 형태로 발전할 것으로 예상된다. 향후 인공지능 모델의 완성도가 갖추어지면 디바이스에서의 저전력이 관건이 되므로 GPU 대비 성능과 전력 효율 향상에 유리한 ASIC이 궁극적인 형태가 될 것으로 예상된다.
온디바이스 AI는 AI 알고리즘을 클라우드 서버가 이닌 데이터가 수집되는 위치 가까이에 있는 디바이스에서 구현 가능하게 한 것이다. 온디바이스 AI는 디바이스에서 데이터 연산을 더욱 빠르게 할 수 있도록 한다. 온디바이스 AI는 데이터를 기기 위치 가까이에 저장할 수 있어, AI 알고리즘이 인터넷 연결 여부에 관계없이 기기에서 생성된 데이터를 처리, 실시간 피드백을 제공할 수 있다. 온디바이스 AI를 사용하면 거의 즉시 대응이 가능하고 일부 민감한 데이터가 실제로 디바이스를 벗어나지 않으므로 보안성이 우수하다.
국내 중소·중견 팹리스들은 다양한 분야에서 특화 AI 반도체 개발과 상용화를 활발히 추진하고 있다.
사피온은 SKT에서 분사하였고 6.7kFPS/60W의 추론용(서버용) AI 반도체 SapeonX220을 개발하고 AI 반도체 벤치마크 MLPerf에서 상용화 등급을 인정받았다. SKT의 5G 인공지능 서비스 및 자율 주행차 등의 상용화를 추진 중이다.
퓨리오사 AI는 AI 반도체 벤치마크 MLPerf에서 엔비디아의 T4 4배 성능으로 영상 인식에 특화된 Warboy를 개발하였다. 추론 성능에서 엔비디아 A100과 경쟁이 가능한 기술로 발표하였다. 자율주행차・클라우드・의료 분야 영상 진단 등 최첨단 기술에 활용되며 카카오, 네이버 등에서 사업화를 추진 중이다.
리벨리온은 금융에 특화된 아이온칩을 발표하였는데 인텔 Goya보다 성능이 30% 우수하다. 실시간 트레이딩에 적합한 금융 분야 AI 응용에서 엔비디아 A100보다 연산 속도는 10배 빠르고, 전력 소모는 10W로 경쟁 제품의 10% 수준이다.
딥엑스는 온디바이스, 자율주행차, 클라우드 서버 등 각 애플리케이션에 특화된 제네시스를 개발하였는데 테슬라 대비 5배 이상의 연산 성능으로 10TOPS/W의 우수한 전력 효율을 갖는다.
디퍼아이는 AI 반도체를 내장한 CCTV 및 로봇용의 AI 반도체 SoC를 양산할 예정으로 다수의 AI 반도체 개발 특허를 보유하고 있으며 온디바이스 AI 반도체를 위한 기술을 독자 확보하고 있다.
3. 차세대반도체 사업단 인공지능 반도체 맞춤형 교육과정
신기술 발달 등 사회변화 속도가 급격해지면서 기존 대학의 인력 양성, 진로·취업지원 시스템만으로는 한계라는 지적이 일고 있다. 최근 기업 채용 방식이 정규 공채에서 수시 채용으로 전환되고 산학 협력을 통해 학생들에게 직무 경험을 제공할 필요성이 강조되고 있다. 산업계 수요에 비해 대학교에서 양성하는 반도체 인력이 부족한 상황에서, 전기/전자 계열 전공이 아닌 학생들도 최소한의 기간에 체계적인 교육을 받아 반도체 업계로 진출할 길을 열어주기 위해서는 산업계 눈높이에 맞는 실무 중심 교육이 요구된다.
차세대 반도체 혁신융합대학 사업단은 다양한 전공의 학생들이 자신이 원하는 진로를 탐색하고, 적성에 맞는 분야를 스스로 결정할 기회를 가질 수 있도록 다양한 수준의 반도체 분야 지식과 경험을 배울 수 있는 맞춤형 교육을 제공한다. 이를 통해 반도체 기술을 확산하고 비전공 학생들에게 새로운 기회를 제공할 방침이다. 수요 맞춤형의 유연한 학사 제도로 4차 산업혁명 시대에 차세대 반도체 분야를 이끌어 나갈 책임감 있는 미래 인재 양성을 목표로 강원대, 대구대, 서울대, 숭실대, 조선이공대, 중앙대, 포항공대 7개 대학이 컨소시엄을 구성하여 교과 과정을 공동 개발·운영하고 있다. 다양한 전공의 학생을 대상으로 교육을 진행하여야 하므로 교양과정부터 초급/중급/고급 과정, 전문 과정, 심화 과정으로 나누어 수준별 교과목을 개발하였다. 마이크로 디그리, 부·복수전공, 연계전공, 심화전공, 학·석사 연계 과정 등의 다양한 교육과정을 개발하였다.
AI 반도체에 대한 산업계의 활동과 인력 수급 요구가 증대됨에 따라서 이에 대응하기 위한 AI 반도체 인력 양성에 특화된 교과목과 교육과정을 운영 중이고 산업체와 협업을 통하여 새로운 교과목을 개발 중이다. 사업 초기부터 지능형 반도체 소자, 인공지능 반도체 소자 설계 프로젝트, 인공지능 반도체 회로 설계 프로젝트, 인공지능 시스템 설계 프로젝트, 인공지능 하드웨어 설계 프로젝트, 인공지능 신경망 회로, 뉴로모픽의 이해 등 AI 반도체 교과목을 운영 중이다. 2023년도에 인공지능 반도체 기술 및 응용 과목을 개발하였는데 LLM(Large Language Model), 금융거래, Biomedical 등 다양한 분야에서의 AI 반도체 활용 방안과 AI 반도체의 다양한 실활용 사례를 현재 세계 최고 AI 반도체 기업인 엔비디아의 미국, 독일, 싱가포르, 한국 등의 현직 엔지니어들이 참여해 배운다. 또한 2024년도에는 산업체의 의견을 수렴하여 신규 교과과정인 인공지능 반도체 마이크로 디그리를 신설할 예정이다.
학생들에게 반도체 시스템 설계와 문제 정의 과정을 스스로 탐구하고 해결하는 기회를 제공하기 위하여 무인 판매대 상품 인식 인공지능 경진 대회, 딥러닝 하드웨어 경진 대회, AI 반도체 회로 설계 경진 대회 등을 운영하고 있다. 특히 AI 반도체 경진 대회는 전국 대학생들에게 참여 기회가 제공되고 있다. 이는 반도체 설계 교육을 받고 AI 반도체 설계 과제를 수행하는 대회로, 학생들의 관심이 증대되고 결과물의 수준도 높아 학생들의 문제 해결 능력 향상에 큰 도움이 되고 있다. 사업단은 앞으로도 이를 지속적으로 발전시키고 다듬어 나가야 할 교육의 한 형태로 주목하고 지원할 계획이다.
온디바이스 AI가 제공할 새로운 서비스를 구현하기 위해 AI 반도체의 수요가 증가할 것으로 보이며, 따라서 국내 반도체 기업들이 새로운 기회를 맞이할 것으로 예상된다. 다만 이러한 AI 반도체 산업 발전의 선결 과제는 인력 양성이다. 차세대 반도체 혁신융합대학 사업단의 AI 반도체 인력 양성 맞춤형 교육과정이 관련 산업 발전에 기여하기를 기대해본다.