Algorithm/Hardware Co-Design for Efficient AI Computing
Professor Jae-Joon Kim
- Designing high-performance and cost-effective solutions for AI computing
- Moving computing to the data, rather than the other way around
- Making lightweight neural networks
Professor Jae-Joon Kim, from the Department of Electrical and Computer Engineering leads the Very-Large Integrated Circuit (VLSI) Research Lab. The laboratory is dedicated to advancing the field through the development of core circuits and architectures for energy-efficient artificial intelligence (AI) computing accelerations. Additionally, the lab actively demonstrates innovative algorithms for compressing deep learning models.
AI-related computing is rapidly becoming a dominant force within the broader landscape of cloud computing, fueled by the escalating demand for generative AI models. However, the surge in model sizes, which is crucial for achieving high-quality results, presents a significant challenge, requiring substantial semiconductor memory and computational resources. Furthermore, the pressing need for extensive data communication between memory and computing logic calls for larger memory capacity with exceptionally high data bandwidth.
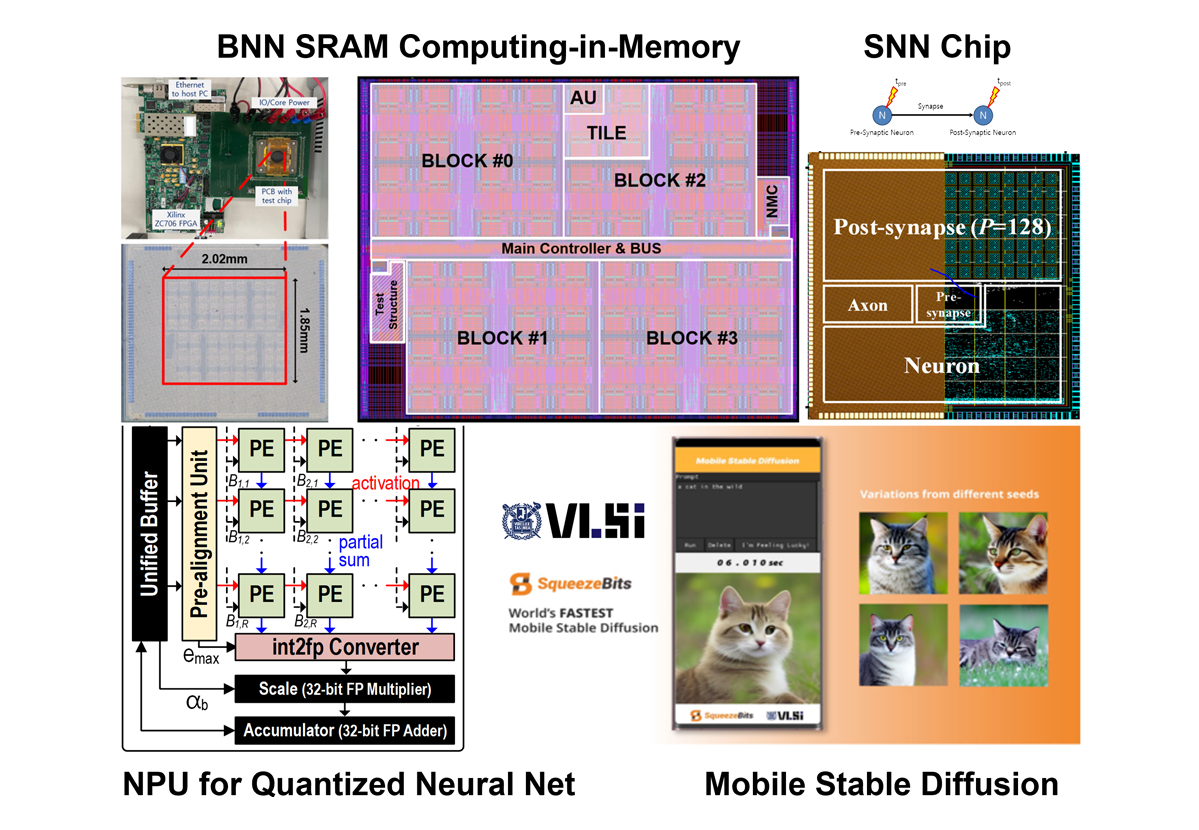
To address the challenges, the SNU VLSI Lab actively pursues a paradigm shift by relocating computing processes to the data itself. A primary focus is on analog in-memory computing, where data is processed within the memory in an analog fashion, eliminating the need for external transmission. Research efforts include AI-optimized circuit structures and architectures utilizing various semiconductor memory types. The VLSI lab has also pioneered approaches to tailor neural network models to the unique characteristics of analog in-memory computing hardware, particularly in addressing sensitivity to noise1-3.
Expanding on this initiative, the lab explores a novel architecture that strategically embeds digital blocks essential for AI computing inside or near semiconductor memories like DRAM and Flash memories. These designs aim to capitalize on the abundant memory bandwidth for highly efficient data communication. The VLSI lab believes that these innovations will enhance South Korea's memory business by introducing new value to the existing DRAM and Flash memory technologies.
In addressing challenges related to massive data communication in AI computing, another research avenue involves data compression without compromising quality. The VLSI Lab consistently explores methods such as quantization to reduce bit precision and pruning to eliminate redundant data in neural networks. The significance of lightweight AI models is particularly pronounced in large language models (LLMs), where the escalating number of parameters demands substantial power and computing resources. Without model compression, LLMs risk becoming prohibitively expensive for widespread use4-7.
The VLSI Lab also designs dedicated accelerators to efficiently compute lightweight neural networks. The lab has demonstrated transformer accelerator architectures which are optimized for LLMs, an NPU optimized for mixed-precision neural nets, and NPUs capable of computing unstructured sparse neural networks more efficiently than previous approaches8-11.
The VLSI Lab takes immense pride in contributing to the industry by transferring its technology to companies in addition to publishing high-quality academic papers. Ultimately, The VLSI Lab's most important mission is to nurture talented individuals who are poised to lead the world in AI computing.
References
- 1 J. Kim et al., Symposium on VLSI Circuits, 2019
- 2 H Kim et al., DAC, 2020
- 3 Y. Kim et al., ISLPED, 2018
- 4 H. Kim et al., ICLR 2020
- 5 Y. Kim et al., Neurips 2022
- 6 D. Ahn et al., ICLR 2019
- 7 H. Kim et al., CVPR 2021
- 8 J. Jang et al., HPCA 2024
- 9 Y. Kim et al., ICLR 2023
- 10 S. Ryu et al., DAC, 2019
- 11 J. Park et al., MLSys, 2020