New Computer Design for the Age of Generative AI and Beyond
Professor Jae W. Lee
- Custom accelerator chip design for machine learning algorithms
- Hardware and software co-design for big data processing
- Algorithm and software optimizations for machine learning and big data processing
The Architecture and Code Optimization Lab (ARC Lab), led by Prof. Jae W. Lee in the Department of Computer Science and Engineering, focuses on innovative computer designs tailored for AI and big data processing. As of April 2024, Prof. Lee guides 16 Ph.D. and 4 master's students in conducting research on topics like custom machine learning (ML) hardware and software optimization, hardware/software co-design for big data processing, and memory system architectures for future computing platforms.
The explosive growth of generative AI has led to a massive increase in the amount of computing resources required for training and inference of ML models. Serving ChatGPT could cost OpenAI over $700,000 per day to operate1, and the training cost of the GPT-4 model reportedly exceeds $100M2. Conventional general-purpose computers utilizing CPUs cannot meet the desired performance, power efficiency, and cost requirements due to the rapid expansion of ML applications.
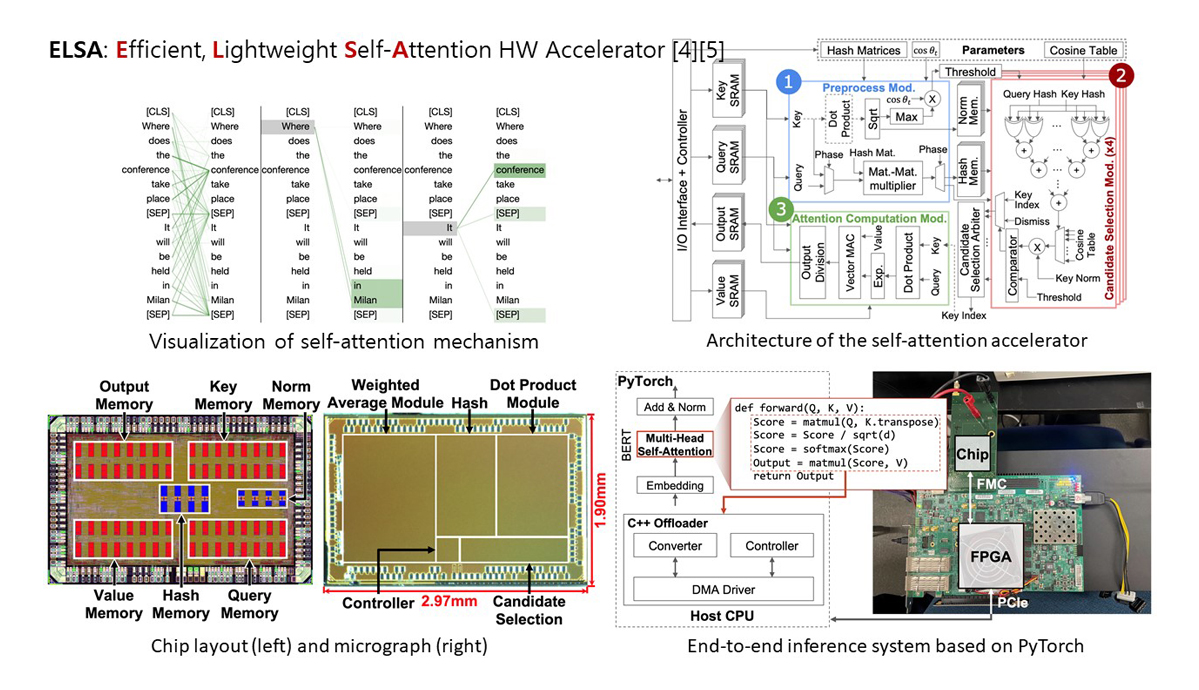
To address this challenge, the ARC Lab focuses on developing hardware specialized for ML task acceleration. The lab embraces a holistic co-design methodology, producing software tailored to this ML-specific hardware as well. For instance, Prof. Lee's team introduced A3, the first custom hardware accelerator aimed specifically at the attention mechanism-the key operation for generative AI models with trillion-scale parameters. Its successor, ELSA4-5, advances execution efficiency and broadens algorithmic applicability. These innovations underscore the benefits of co-designing algorithm and hardware, pushing the boundaries of algorithmic optimization well beyond the capabilities of today's GPUs. Both designs have been successfully prototyped using TSMC's 40nm CMOS technology. The ARC Lab strives to provide comprehensive solutions that enable efficient and cost-effective execution of ML workloads, ultimately keeping pace with the ever-increasing demands of the generative AI era.
In addition to the AI/ML-focused research, the ARC Lab is actively conducting research on specialized architectures for non-ML workloads. The lab is developing various accelerator architectures specifically designed for big data processing, with a particular emphasis on tasks like search6-7, vector database8, genomic analysis9, and data analytics10. Again, these specialized hardware designs are complemented by the development of software frameworks that support and optimize the execution of big data workloads on the accelerators. By creating a synergistic combination of domain-specific hardware and software, the ARC Lab aims to provide efficient and cost-effective solutions for the ever-growing demands of big data processing, ensuring that these systems can keep pace with the increasing complexity and scale of data-intensive applications.
Finally, the ARC Lab's research efforts extend beyond hardware to include extensive work in the algorithm and software domain. As previously mentioned, the proliferation of ML and big data applications has led to an explosive growth in the demand for memory and storage resources. However, traditional software stacks struggle to meet the stringent requirements of performance, power efficiency, and cost-effectiveness posed by these data-intensive workloads. Recognizing this challenge, the ARC Lab is actively investigating novel software stack designs, with emphasis on leveraging emerging memory and storage devices. For example, Prof. Lee's team proposes to leverage emerging nonvolatile memory and high-performance SSDs to lessen the memory capacity wall for graph neural network training11 and key-value stores12-13. There are other proposals from his team that propose a novel lossless image compression format for high-throughput training of deep neural networks (DNNs)14 and pruning and quantization techniques15-16. By optimizing and tailoring these components to the unique characteristics of ML and big data workloads, the ARC Lab strives to unlock the full potential of the underlying hardware while ensuring optimal resource utilization and cost-efficiency.
In conclusion, the ARC Lab's comprehensive approach to tackling the challenges posed by the rapid advancement of AI sets it apart as a leader in the field. The lab's unique strength lies in its ability to cultivate a new generation of researchers who possess a deep understanding of both hardware and software. By fostering a culture of collaboration and cross-pollination between hardware and software researchers, the ARC Lab is creating a synergistic environment where groundbreaking ideas can flourish. With their cutting-edge research and dedication to pushing the boundaries of what is possible, the ARC Lab is poised to make significant contributions to the fields of AI and big data, shaping the future of computing for years to come.
References
- 1 Aaron Mok, "ChatGPT Could Cost over $700,000 per Day to Operate. Microsoft Is Reportedly Trying to Make It Cheaper", Business Insider, April 2023.
- 2 Will Knight, "OpenAI's CEO Says the Age of Giant AI Models Is Already Over", Wired Magazine, April 2023.
- 3 Tae Jun Ham, Seonghak Kim, and Sung Jun Jung, Young H. Oh, Yeonhong Park, Yoon Ho Song, Junghoon Park, Sanghee Lee, Kyoung Park, Jae W. Lee, and Deog-Kyoon Jeong, "A^3: Accelerating Neural Network Attention Mechanism with Approximation", 26th IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, California, February 2020.
- 4 Tae Jun Ham*, Yejin Lee*, Seong Hoon Seo, Soosung Kim, Hyunji Choi, Sung Jun Jung, and Jae W. Lee, "ELSA: Hardware-Software Co-design for Efficient, Lightweight Self-Attention Mechanism in Neural Networks", 48th IEEE/ACM International Symposium on Computer Architecture (ISCA), Valencia, Spain, June 2021.
- 5 Seong Hoon Seo*, Soosung Kim*, Sung Jun Jung, Sangwoo Kwon, Hyunseung Lee, and Jae W. Lee, "A 40nm 5.6TOPS/W 239GOPS/mm² Self-Attention Processor with Sign Random Projection-based Approximation", 48th European Solid-State Circuits Conference (ESSCIRC), Milan, Italy, September 2022.
- 6 Jun Heo, Jaeyeon Won, Yejin Lee, Shivam Bharuka, Jaeyoung Jang, Tae Jun Ham, and Jae W. Lee, "IIU: Specialized Architecture for Inverted Index Search", 25th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Lausanne, Switzerland, March 2020.
- 7 Jun Heo, Seung Yul Lee, Sunhong Min, Yeonhong Park, Sung Jun Jung, Tae Jun Ham, and Jae W. Lee, "BOSS: Bandwidth-Optimized Search Accelerator for Storage-Class Memory", 48th IEEE/ACM International Symposium on Computer Architecture (ISCA), Valencia, Spain, June 2021.
- 8 Yejin Lee, Hyunji Choi, Sunhong Min, Hyunseung Lee, Sangwon Baek, Dawoon Jeong, Jae W. Lee, and Tae Jun Ham, "ANNA: Specialized Architecture for Approximate Nearest Neighbor Search", 28th IEEE International Symposium on High Performance Computer Architecture (HPCA), Seoul, South Korea, April 2022.
- 9 Tae Jun Ham, David Bruns-Smith, Brendan Sweeney, Yejin Lee, Seong Hoon Seo, U Gyeong Song, Young H. Oh, Krste Asanovic, Jae W. Lee, and Lisa Wu Wills, "Genesis: A Hardware Acceleration Framework for Genomic Data Analysis", 47th IEEE/ACM International Symposium on Computer Architecture (ISCA), Valencia, Spain, May 2020.
- 10 Jaeyoung Jang, Sung Jun Jung, Sunmin Jeong, Jun Heo, Hoon Shin, Tae Jun Ham, and Jae W. Lee, "A Specialized Architecture for Object Serialization with Applications to Big Data Analytics", 47th IEEE/ACM International Symposium on Computer Architecture (ISCA), Valencia, Spain, May 2020.
- 11 Yeonhong Park, Sunhong Min, and Jae W. Lee, "Ginex: SSD-enabled Billion-scale Graph Neural Network Training on a Single Machine via Provably Optimal In-memory Caching", 48th International Conference on Very Large Databases (VLDB), Sydney, Australia, September 2022.
- 12 Jongsung Lee, Donguk Kim, and Jae W. Lee, "WALTZ: Leveraging Zone Append to Tighten the Tail Latency of LSM Tree on ZNS SSD", 49th International Conference on Very Large Databases (VLDB), Vancouver, Canada, August 2023.
- 13 Donguk Kim, Jongsung Lee, Keun Soo Lim, Jun Heo, Tae Jun Ham, and Jae W. Lee, "An LSM Tree Augmented with B+ Tree on Nonvolatile Memory", ACM Transactions on Storage, January 2024.
- 14 Jonghyun Bae, Woohyeon Baek, Tae Jun Ham, and Jae W. Lee, "L3: Accelerator-Friendly Lossless Image Format for High-Resolution, High-Throughput DNN Training", European Conference on Computer Vision (ECCV), Tel-Aviv, Israel, October 2022.
- 15 Jaeyeon Won, Jeyeon Si, Sam Son, Tae Jun Ham, and Jae W. Lee, "ULPPACK: Fast Sub-8-bit Matrix Multiply on Commodity SIMD Hardware", Fifth Conference on Machine Learning and Systems (MLSys), Santa Clara, California, August 2022.
- 16 Yejin Lee, Donghyun Lee, JungUk Hong, Jae W. Lee, and Hongil Yoon, "Not All Neighbors Matter: Point Distribution-Aware Pruning for 3D Point Cloud", 37th AAAI Conference on Artificial Intelligence, Washington, DC, February 2023.